La création interactive
Forth n'est pas seulement un langage, c'est aussi (et avant tout ?) un environnement interactif de développement. Il est possible dans une session de compiler des mots additionnels au dictionnaire. Le mot principal pour opérer est :.
Par exemple :
: AJOUTE_2 2 +
Cela définit un mot qui ajoute 2 à la valeur au sommet de la pile.
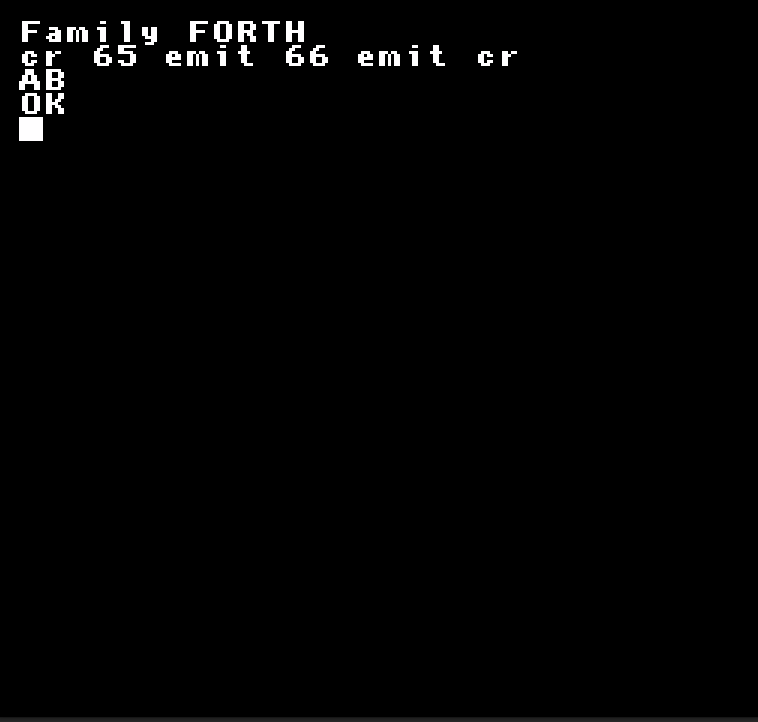
100 AJOUTE_2 .
... affiche donc 102 à l'écran (le mot . affiche le contenu du sommet de la pile en tant que nombre).
Structure d'un mot
Il avait déjà été question de la structure d'un mot dans un Forth 8 bits classique lors de la partie 6 de ces articles. Ça remonte un peu. On peut aussi trouver des éléments dans la documentation de Pampuk Forth que j'avais écrite il y a un moment.
Rapidement, un mot est composé d'un NFA (longueur du nom et drapeaux, ainsi que le nom), d'un LFA (lien vers le mot précédent dans le dictionnaire), d'un CFA (adresse du code assembleur à exécuter pour ce mot) et d'un PFA (les paramètres).
Chaque nouveau mot se place à la suite des précédents, donc à l'emplacement désigné par HERE. Lorsque l'on sait qu'il existe un mot C, qui place la valeur au sommet de la pile en HERE en tant qu'octet et avance HERE (, fait la même chose pour une cellule complète), on peut donc tout à fait compiler un nouveau mot « à la main » :
HEX \ passage en hexadécimal
HERE \ garder la valeur de HERE sur la pile pour plus tard
03 C, \ longueur du mot
4D C, \ M
4F C, \ O
D4 C, \ T (54) et bit 7 (80) du dernier caractère du mot à 1
LATEST , \ LFA : lien vers le dernier mot défini du dictionnaire
' DOVAR CFA , \ CFA : compile le CFA de DOVAR (qui met sur la pile le contenu de la première cellule du PFA)
0000 \ PFA : le contenu de la variable... 0
CURRENT @ ! \ met à jour le dictionnaire en y incluant ce mot
\ grâce à l'adresse HERE mise sur la pile au début
Voilà donc comporte comme une variable. Il manque des mots actuellement pour que cela fonctionne (DOVAR n'est pas accessible directement, ', C, et , non plus, CURRENT concerne la gestion du dictionnaire, que j'ai mis de côté pour le moment).
Imaginez faire ça pour chaque nouveau mot... Forth propose donc des mots pour répéter ce procédé. Et comme tout en Forth, il n'y a pas de procédé magique, créer un nouveau mot se fait avec d'autres mots.
Création de l'entête
C'est le mot CREATE qui se charge de construire un mot. Son implémentation commence de la même manière que FIND, en allant chercher le nom d'un mot dans le flux d'entrée pour le normaliser et le mettre à HERE.
: CREATE
BL WORD \ récupération du mot
HERE COUNT CAPITAL \ passage en majuscules
(HEADER) \ création de l'entête
;
(HEADER) est un mot écrit en assembleur qui met en place l'en-tête. C'est assez simple car WORD a posé une chaîne préfixée par sa longueur à HERE, c'est-à-dire pile à l'endroit où sera la NFA du nouveau mot. C'est bien fait non ?
Il faut donc mettre le bit 7 du dernier caractère du nom du mot à 1 (merci l'indexage par Y), ajouter le flag SMUDGE à la longueur puisque le mot n'est pas encore validé (voir paragraphe suivant), et mettre la valeur de LATEST au LFA. Le CFA est celui de DOVAR, qui exécute une variable, car c'est un mot sûr : il pousse sur la pile sa propre adresse PFA. Pas de danger.
Enfin, HERE est placé au PFA et le dictionnaire est mis à jour. Comme c'est un mot assembleur interne, on peut directement manipuler la valeur de LATEST, qui devrait sinon passer par CURRENT, dont on ne dispose pas.
Tout est prêt pour compléter le mot ! Il faut ajouter le vrai contenu du PFA et changer le CFA pour le type de mot que l'on veut, en mettant à jour HERE. Avec , et C, par exemple, mais aussi pourquoi pas, avec ALLOT.
ALLOT ? Je n'en avais pas parlé mais il est logique de l'implémenter maintenant, même s'il n'est pas encore utilisé. C'est un mot qui réserve de la place en mémoire. La place en mémoire réservable en Forth est à HERE. Ce que fait ALLOT est donc juste ajouter à HERE le nombre d'octets que l'on veut réserver.
10 ALLOT \ réserve 10 octets, autrement dit, ajoute 10 à HERE
Les drapeaux du NFA
Il y a deux drapeaux qui sont mêlés à la longueur dans le NFA d'un mot, SMUDGE et IMMEDIATE, qui sont aussi les noms des mots qui permettent de manipuler ces drapeaux.
SMUDGE est placé lors de la création d'un mot, pour éviter que FIND le trouve alors que celui-ci n'est pas complet. C'est en quelque sorte un panneau indiquant en construction. Lorsqu'un mot est complètement terminé, le drapeau SMUDGE est enlevé grâce au mot du même nom (qui est en fait une bascule, SMUDGE SMUDGE revient à ne rien faire).
Bien entendu, il a fallu adapter FIND (ou plus exactement (FIND)) pour que l'algorithme saute par-dessus les mots dont le drapeau SMUDGE est à 1.
IMMEDIATE est un autre drapeau qui indique que le mot est immédiat... On verra cela lorsqu'on reviendra sur INTERPRET. Mais brièvement voici le principe : lorsqu'on est en train de compiler un mot, INTERPRET se contente de compiler les CFA des mots, ainsi que les nombres, à la suite de HERE. Un mot immédiat est une exception qui dit : ce mot-là ne doit pas être compilé, mais exécuté, même si on est en mode compilation.
Cela permet de travailler sur la compilation elle-même. Et le premier usage est assez important : pouvoir sortir du mode de compilation !
Le mot IMMEDIATE est aussi une bascule, et tout comme SMUDGE agit sur le dernier mot qui a été défini dans le dictionnaire (LATEST).
Interprétation de la compilation
Comme indiqué ci-dessus mais aussi dans les articles précédents concernant INTERPRET, le mot a deux comportements différents suivant s'il est en mode exécution (le mode implémenté pour le moment) ou en mode compilation (le mode à ajouter pour pouvoir implémenter :).
Rappel d'INTERPRET avec juste la partie exécution :
: INTERPRET
BEGIN
-FIND IF
DROP \ oublie la longueur du nom retourné par -FIND
CFA EXECUTE
ELSE
HERE
C@ 0= IF EXIT THEN \ fin de la boucle, quitte le mot
HERE NUMBER \ convertit en nombre
ENDIF
AGAIN ;
Voici le code incluant la partie compilation :
: INTERPRET
BEGIN
-FIND IF \ ça ne change pas, on commence par chercher le mot à interpréter
STATE @ \ et on vérifie le mode actuel. Si c'est 128, on est en mode
\ compilation. 0, en mode exécution
U< \ si la longueur/drapeau est inférieur à STATE en non signé,
\ c'est que STATE était égal à 128 et le drapeau IMMEDIATE n'était
\ pas placé
IF \ c'est donc une compilation
CFA \ récupération du CFA depuis le PFA retourné par -FIND
, \ compilation du CFA (c'est-à-dire, ajoute le CFA à HERE, avec
\ HERE normalement dans le PFA d'un mot en cours de création)
ELSE
CFA EXECUTE \ exécution du mot, qu'on soit en mode de compilation
\ ou bien que ce soit un mot immédiat
ENDIF
ELSE
HERE
C@ 0= IF EXIT THEN \ fin de la boucle, quitte le mot
HERE NUMBER \ convertit en nombre
LITERAL \ voir ci-dessous
ENDIF
AGAIN ;
Comme on peut le voir, le changement est globalement de vérifier STATE et savoir si le mot est immédiat ou pas. Si cela indique une compilation, le CFA est compilé dans le PFA du mot. Attention, comme souvent, Forth part du principe que tout s'enchaîne logiquement. Il vaut mieux être en train de compiler un mot, sinon, on ajoute des CFA dans HERE sans effet (ce qui n'est pas non plus très grave, ça fait juste perdre de la place).
Pour la partie nombre, un nouveau mot s'occupe de tout : LITERAL. En mode exécution, ce mot ne fait rien et laisse le nombre sur la pile. En mode compilation, le mot compile un LIT suivi du nombre trouvé sur la pile, compilant de fait la mise sur la pile d'un nombre, lors de l'exécution future.
Pour implémenter INTERPRET, il manque U<, une comparaison non signée, et STATE, une variable qui est initialisée lors du reset de l'environnement (dans COLD). J'en ai profité pour implémenter quelques mots de comparaison (<, >, 0>).
LITERAL est le genre de mots Forth pour lesquels un peu de gymnastique est nécessaire :
: LITERAL
STATE @ IF \ compilation ?
IF
LIT ' LIT \ met le CFA de LIT sur la pile (grâce au premier LIT)
, \ compile le CFA de LIT
, \ compile le nombre
ENDIF
;
Deux-points et point virgule
C'est bon, j'ai tout pour implémenter les deux mots centraux dans la création de mots Forth de manière interactive à partir d'autres mots Forth.
Quelles sont les étapes ?
- Créer un mot. Pour ça, on a
CREATE. - Changer le
CFAdu mot pour que ce soitDOCOL(l'interpréteur de mots Forth). - Passer en mode compilation, pour que
INTERPRETcompile les mots qui suivent. - Compiler
;Sen dernier mot. - Valider le mot avec
SMUDGE. - Sortir du mode compilation.
Les étapes 1, 2 et 3 sont la responsabilité de :. Les étapes 4, 5 et 6 celles de ;.
Voilà à quoi cela ressemble :
HEX
: : \ oui, bon, définir : avec lui-même ne fonctionne pas
\ mais c'est une manière de l'écrire
CREATE \ création du mot
LIT DOCOL \ adresse de DOCOL (voir note ci-dessous)
HERE CFA \ le CFA du mot actuel (qui est actuellement sur le PFA)
\ pourrait aussi s'écrire LATEST PFA CFA
! \ patch du CFA du mot qui vient d'être créé
80 STATE !\ passe en mode compilation
; \ bon... là aussi, on ne l'a pas encore défini...
Deux commentaires. Le premier est que ce n'est pas l'implémentation classique pour patcher le CFA du mot qui vient d'être créé. L'implémentation classique est d'utiliser ;CODE, qui est l'équivalent de ; pour les mots créés par CODE. Le mot patch le CFA pour le faire pointer vers l'adresse qui suit le mot, qui doit contenir du code en assembleur. L'astuce est alors de faire suivre : par le code de DOCOL, et hop... Je réimplémenterai peut-être ça de cette manière, mais pour l'explication, c'est plus simple de détailler comme ci-dessus.
Autre commentaire : 80 STATE ! a un nom, c'est le mot ]. Le mot [, lui, passe en mode interprétation en faisant 0 STATE !. Et ce sont deux mots immédiats.
Cela permet, lors de la compilation d'un mot par :, de sortir temporairement du mode compilation pour effectuer des opérations. Cela encadre élégamment le code interprété entre [ et ], ce qui se comprend bien visuellement.
Et pour ;
: ;
' ;S , \ voir note ci-dessous
SMUDGE \ le mot devient visible
LIT 0 STATE ! \ voir le commentaire ci-dessus !
; \ oui oui... certes certes
IMMEDIATE \ le mot doit être immédiat, sinon, il serait compilé
\ dans le mot en train d'être défini
' ;S , se lit : prendre le CFA de ;S et le compiler. C'est ce que l'on veut. Mais il y a un mot pour ça : COMPILE. Ce mot prend le mot qui suit (dans un mot compilé), prend son CFA et le compile.
Avec toutes ces notes, cela donne au final :
: : CREATE LIT DOCOL HERE CFA ! ] ;
: ; COMPILE ;S [ ; IMMEDIATE
Création de mots
Enfin, la création de mots est possible. On peut écrire, par exemple : DOUBLE DUP + ; qui définit un mot qui double le nombre sur le haut de la pile.
Mais il n'y a toujours pas de mots pour afficher les nombres.
Toute cette suite de définition des mots standards n'est pas très intéressante. Je vais prendre leurs implémentations et les traduire en mode « ROM ». La plupart sont des transcriptions directes, seuls ceux avec des branchements doivent être un peu adaptés. Je reviendrai avec un article lorsqu'il y aura du nouveau intéressant.